|
io-chess
UCI chess engine
|
|
io-chess
UCI chess engine
|
The evaluation subsystem assigns a numerical score to any chess position, estimating how favourable it is for the side to move. This score guides the search algorithm: a higher score means the position is better for the side to move.
The primary evaluator is a Factorized Mixture-of-Experts (MoE) network that has been trained on hundreds of millions of positions and compiled to native C++ with SIMD-optimised inference. No external ML runtime (ONNX, TensorFlow, etc.) is required.
The network consists of three main components:
| Expert | Specialisation | Typical positions |
|---|---|---|
| Expert 0 | Tactical | Checks, captures, pins, forks |
| Expert 1 | Strategical | Pawn structure, piece activity, space |
| Expert 2 | Major-piece endgame | Rook endings, queen endings |
| Expert 3 | Minor-piece endgame | Bishop/knight endings, opposite-colour bishops |
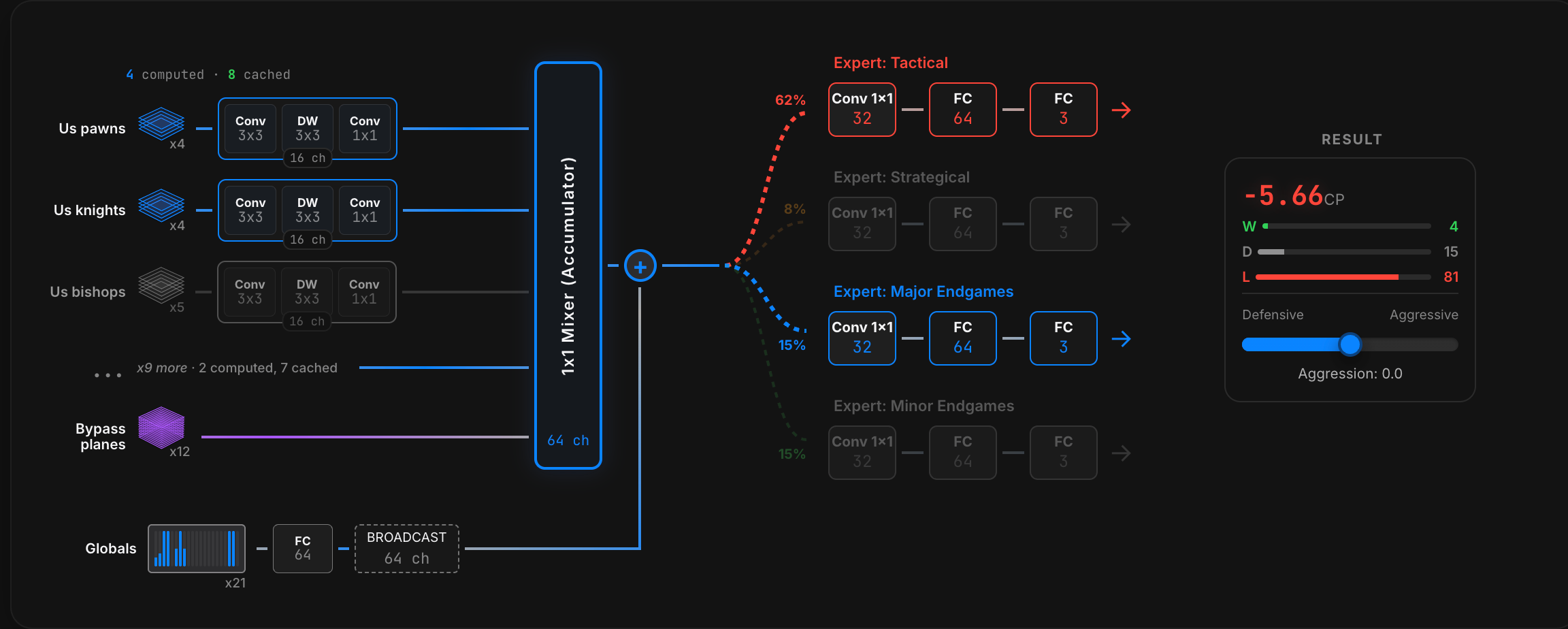
Rather than recomputing all feature planes from scratch on every ply of the search tree, the engine maintains a double-accumulator that tracks incremental feature deltas as pieces move. When a move is made:
This makes evaluation extremely fast inside the search tree — typically under 1 μs per position on modern hardware.
When no neural network weights are loaded, the engine falls back to a classical evaluation implemented in SimpleEvalContext. This evaluator uses:
While far weaker than the neural evaluation, the heuristic fallback allows the engine to play reasonable chess without any external data files.
Internal centipawn scores are converted to Win/Draw/Loss (WDL) probabilities using a logistic model fitted to self-play data. This enables the engine to report UCI wdl statistics and allows the search to make draw-aware decisions (e.g. avoiding drawn endgames when ahead).