|
io-chess
UCI chess engine
|
|
io-chess
UCI chess engine
|
Classes | |
| class | ChunkedRandomSampler |
| class | ExpertChunkedSampler |
| class | ConcatChunkedRandomSampler |
| class | ConcatExpertChunkedSampler |
Functions | |
| print_header (text) | |
| format_time (seconds) | |
| get_device () | |
| init_wandb (args, phase_name) | |
| build_loader (dataset, batch_size, shuffle, workers, custom_sampler=None) | |
| parse_data_roots (args) | |
| resolve_data_splits (data_roots) | |
| build_phase14_datasets (data_roots, n_globals) | |
| phase_eta_min (phase) | |
| build_scheduler (optimizer, total_steps, warmup_steps, eta_min) | |
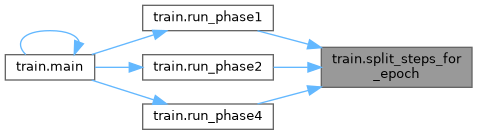
| split_steps_for_epoch (total_steps, val_splits) | |
| arch_string (args) | |
| phase1_export_state_dict (model) | |
| save_model_checkpoint (path, model, phase, epoch, val_terms, args, extra=None, state_dict_override=None) | |
| empty_loss_terms () | |
| add_loss_terms (sums, total_t, wdl_t, n) | |
| finalize_loss_terms (sums, total_samples) | |
| format_loss_terms (tag, terms, color) | |
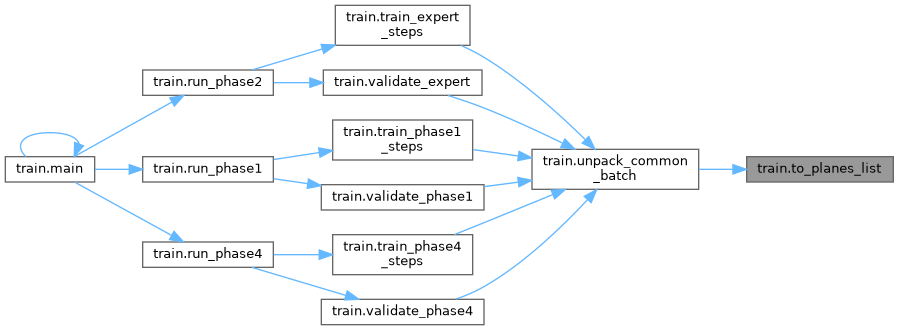
| to_planes_list (branches) | |
| top2_sparse_weights (base_weights) | |
| unpack_common_batch (batch, device) | |
| forward_backbone (model, planes_list, bypass, global_feats) | |
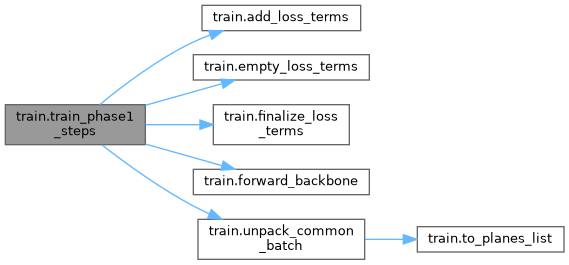
| train_phase1_steps (model, data_iter, num_steps, optimizer, scheduler, device) | |
| validate_phase1 (model, loader, device) | |
| copy_expert0_to_all (model) | |
| run_phase1 (model, args, wandb_run=None) | |
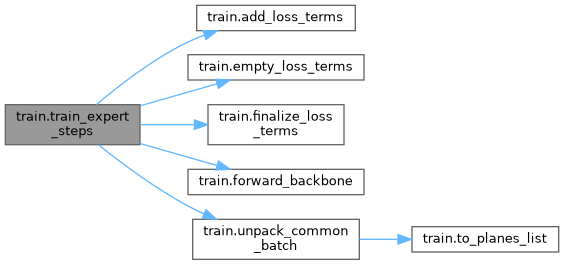
| train_expert_steps (model, expert_idx, data_iter, num_steps, optimizer, scheduler, device) | |
| validate_expert (model, expert_idx, loader, device) | |
| load_checkpoint_into_model (model, checkpoint_path, device) | |
| run_phase2 (model, args, wandb_run=None) | |
| train_phase4_steps (model, data_iter, num_steps, optimizer, scheduler, device) | |
| validate_phase4 (model, loader, device) | |
| run_phase4 (model, args, wandb_run=None) | |
| main () | |
Variables | |
| bool | WANDB_AVAILABLE = True |
| C = Colors | |
@file train.py @brief Training script for model.py (factorized MoE). 3-Phase training pipeline: Phase 1: Base training with teacher routing weights Phase 2: Expert specialization on expert-specific datasets Phase 4: Joint fine-tuning with top-2 routing This script is intentionally styled after train_light_moe.py while using factorized packed inputs from dataset.py.
| add_loss_terms | ( | sums, | |
| total_t, | |||
| wdl_t, | |||
| n ) |
| arch_string | ( | args | ) |
| build_loader | ( | dataset, | |
| batch_size, | |||
| shuffle, | |||
| workers, | |||
| custom_sampler = None ) |
| build_phase14_datasets | ( | data_roots, | |
| n_globals ) |


| build_scheduler | ( | optimizer, | |
| total_steps, | |||
| warmup_steps, | |||
| eta_min ) |
| copy_expert0_to_all | ( | model | ) |

| empty_loss_terms | ( | ) |
| finalize_loss_terms | ( | sums, | |
| total_samples ) |
| format_loss_terms | ( | tag, | |
| terms, | |||
| color ) |
| format_time | ( | seconds | ) |
| forward_backbone | ( | model, | |
| planes_list, | |||
| bypass, | |||
| global_feats ) |
| get_device | ( | ) |
| init_wandb | ( | args, | |
| phase_name ) |
| load_checkpoint_into_model | ( | model, | |
| checkpoint_path, | |||
| device ) |

| main | ( | ) |

| parse_data_roots | ( | args | ) |

| phase1_export_state_dict | ( | model | ) |
Build a checkpoint state where expert0 is copied to all experts.

| phase_eta_min | ( | phase | ) |
| print_header | ( | text | ) |
| resolve_data_splits | ( | data_roots | ) |
| run_phase1 | ( | model, | |
| args, | |||
| wandb_run = None ) |
| run_phase2 | ( | model, | |
| args, | |||
| wandb_run = None ) |
| run_phase4 | ( | model, | |
| args, | |||
| wandb_run = None ) |
| save_model_checkpoint | ( | path, | |
| model, | |||
| phase, | |||
| epoch, | |||
| val_terms, | |||
| args, | |||
| extra = None, | |||
| state_dict_override = None ) |
| split_steps_for_epoch | ( | total_steps, | |
| val_splits ) |
| to_planes_list | ( | branches | ) |
| top2_sparse_weights | ( | base_weights | ) |

| train_expert_steps | ( | model, | |
| expert_idx, | |||
| data_iter, | |||
| num_steps, | |||
| optimizer, | |||
| scheduler, | |||
| device ) |

| train_phase1_steps | ( | model, | |
| data_iter, | |||
| num_steps, | |||
| optimizer, | |||
| scheduler, | |||
| device ) |

| train_phase4_steps | ( | model, | |
| data_iter, | |||
| num_steps, | |||
| optimizer, | |||
| scheduler, | |||
| device ) |

| unpack_common_batch | ( | batch, | |
| device ) |

| validate_expert | ( | model, | |
| expert_idx, | |||
| loader, | |||
| device ) |

| validate_phase1 | ( | model, | |
| loader, | |||
| device ) |

| validate_phase4 | ( | model, | |
| loader, | |||
| device ) |

| train.C = Colors |
| bool WANDB_AVAILABLE = True |